How your Neighbourhood is Classified for Targeted Marketing
The main users of geodemographic segmentation systems have traditionally been commercial direct marketing companies, academics, and large retailers. Latterly they have been accepted by public sector organisations as being very relevant to planning and implementing more efficient services. Peter Sleight explains how eight systems were produced and how they differ.
Every census is now followed – two to three years later – by the launch of a new wave of geodemographic segmentation systems. In 2013/14 there are eight systems aimed at various parts of the market including much more emphasis on the internet as well as conventional direct marketing.
The most notable innovations relate to two key factors; the ability to update, (present in most systems this time), and the heightened importance of digital. These are on top of the real growth in their use since the turn of the century.
The census of population is taken by the Office for National Statistics for England & Wales, by what is now the National Records of Scotland (previously the General Register Office) and by the Northern Ireland Statistics and Research Agency. The production of the output statistics took place on different timescales for the three agencies, so the data has arrived in waves, with the most detailed, ‘small area’ data coming towards the end. Geodemographics systems providers need these small area statistics unless they decide not to use census data at all.
What follows is a summary of the eight systems in order of their appearance from March 2013 through to the near future.
Systems Reviewed
CACI produced the first UK geodemographic classification, Acorn, in 1979 and had apparently been wedded to the census data. This time CACI did not use any census data in their new system – enabling them to launch before other systems in March 2013. John Rae said ‘we didn’t use census data for segmentation, but we waited until we could check our results against census data before launching’. He explained that, with uncertainty over the future of the census, it was prudent to seek an alternative solution and particularly one that could be regularly updated much more frequently.
CACI has used a wide range of datasets, from commercial and public sector open data sources including land registries, commercial sources on age of residents, ethnicity profiles, lifestyle surveys, population density, benefits, social housing and other rental property data. CACI has created proprietary databases including prisons, traveller sites, age-restricted housing, care homes, high-rise buildings and student accommodation.
Acorn classifies postcodes into 6 categories, 18 groups and 62 types. John Rae says ‘We put more effort into Acorn than our competitors. We use more Open Data and make many ‘freedom of information’ requests. We buy in more data from commercial sources and tread the streets to collect key information. This makes Acorn more up to date and accurate’. www.acorn.caci.co.uk
Censation, from AFD Software was built by Tim Drye from Data Talk, and launched in May 2013. This system uses 600 variables from the Census, plus data from the Land Registry and from 80,000 face-to-face interviews every year. It is referenced to residential and transactional data and provides a neighbourhood classification at unit postcode level. The methodology treats the census data as ‘undulating terrain’ rather than as discrete ‘islands’. The product is free with AFD name & address management software. www.afd.co.uk
TRAC Consultancy’s ‘Sonar’ classification was launched in January 2014 and uses census data as well as council tax bands, Land Registry property prices, police crime data, and DWP claimant data. The resultant clusters were grouped by life-stage and affluence. David Griffiths, proprietor of TRAC, said ‘Sonar is the result of using a wide variety of different statistical techniques and combinations of variables to find the most powerful and predictive classification. Testing is key and we always recommend that potential clients try the product for themselves.’ www.tracconsultancy.co.uk
Acxiom’s Personicx avoids census data because testing showed no significant improvement over the use of the other data sources. Personicx works across all levels of geography – postcode, household, and individual, and incorporates a code that denotes ‘digital sophistication’. Personicx is apparently being used within online environments for ad targeting not least in partnerships with Facebook and eBay. This is key to the company’s cross-platform global Audience Operating System.
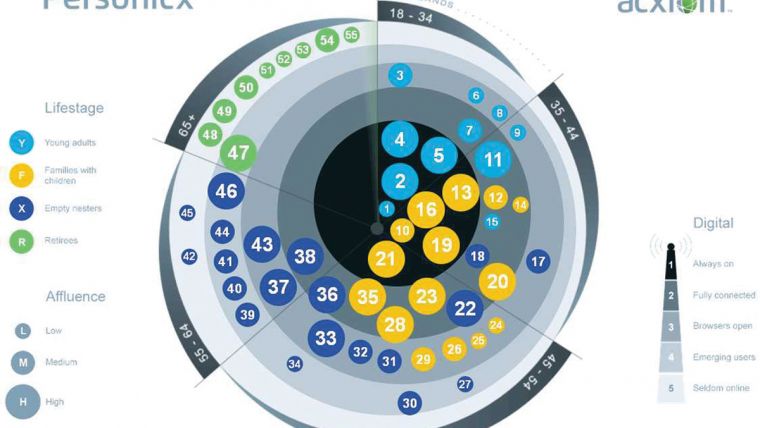
The prime data source is Acxiom’s own on/offline lifestyle survey data for which the company claims responses for over 20 million consumers at their current address. This means that the segmentation performs particularly well at an individual/household level, specifically behavioural variables. Personicx has 55 clusters, driven by behaviour and structured with a five digit code combining lifestage, affluence, digital activity and age. This is visualised with the Personicx ‘Eye’, which can be seen on their website and which enables an intuitive overview of the clusters, segmented by age bands, with life-stage numbers in coloured circles – then click for a pen-portrait of that cluster code.
Clare Woodvine, product manager, said ‘Personicx links the off- and online worlds and can become the common language between traditional CRM-based marketers and digital (agency and publisher) marketers. One segmentation that works across all sectors and all geographic levels simplifies the product, which will also be more accurate by using up-to-date survey data’. www.personicx.co.uk
Experian’s latest version of Mosaic was launched with illustrations of notable changes in UK society since 2001, including the forced move to renting or house sharing as the only affordable option for a large section of the population. The list of data inputs can be seen from Experian’s impressive visualisation tool at www.SegmentationPortal.com
Mosaic is built on the ‘ConsumerView’ picture of all UK adults, using hundreds of millions of input records with actual data at individual and household levels. It aims to optimise the balance of geodemographics and individual/household data, so that the segmentation will be an accurate and reliable classification of households and postcodes.
The visualisation shows the Mosaic build process in detail and also enables viewing of details of all Mosaic types, maps of areas of chosen types, characteristics of people and families within each type. It enables customisation, with client-specific segmentation being built from underlying Mosaic ‘DNA’ building blocks, which can then be viewed – privately of course! Paul Cresswell, VP of product management, said ‘Using advanced analytical techniques and relevant new data, new Mosaic optimises geodemographic and individual data, delivering a stable, robust solution for clients across all marketing channels’.
CAMEO, from Callcredit Information Group, uses census data and Open Data, and is built with dynamic links to its consumer database, Define, which holds details on over 60 million UK residents with actual lifestyle, survey and transactional data. CAMEO is updated dynamically to reflect key life-changes of individuals and Define provides a breadth of consumer insights across ten vertical sectors, and multi-channel behavioural insights from online and offline transaction data. CAMEO, therefore, claims to accurately reflect changing consumer characteristics as their affluence varies or as they go through key life events from setting up home, having children, and retiring.
Callcredit have a new microsite where visitors can explore CAMEO; each segmentation type can be explored using detailed sector-specific descriptors and visualisations. It is built in three tiers; individual, household and postcode. All are built from individual-level granularity. www.cameodynamic.com/uk
Zoe Palethorpe, head of products & propositions, said ‘With ever-expanding availability of data types, we have kept CAMEO flexible enough to incorporate data from new sources. We can add fresh datasets as they become available to provide increasing width for consumer targeting.
The 2011 Area Classification of Output Areas, or OAC, has been produced by University College London (UCL) in collaboration with ONS and is now complete for the whole of the UK.
OAC is a ‘classic’ product using census data only and is free to use. It is a hierarchical classification that assigns each Output Area to 1 of 6 supergroups, 24 groups, and 68 subgroups. Although it is ‘general purpose’, the methodology is flexible, so specialised versions could be produced in future. The product is supported by the renowned UCL CASA mapping.
The ESRC funded Retail Research Data website offers interactive maps of 2011 OAC for England and Wales – the rest of the UK will follow. The Open methodology and use of open source programs means that expert users can either replicate the classification or modify it. www.retailresearchdata.org/2011oac.aspx
The latest product, expected in early 2015, is P2 (P-squared – People & Places) from Beacon Dodsworth. This version will incorporate economic factors, with the ability to update as regional economies change. The company is working with the University of Liverpool, using research carried out by the ‘Centre for Cities’ urban policy research unit.
This team is looking at the 64 Primary Urban Areas in Britain, which are aggregations of local authorities. By relating 11 census variables (e.g. area density, population 65+, qualification level, and economically inactive rate) they have analysed the factors that lead to ‘success or struggle’. The subsequent cluster analysis produces 6 different clusters of local authorities, ‘Urban Clusters’.
Cluster 5, for example, is labelled ‘Regional Growth Centres’ – such as Cambridge with positive variables such as Business Churn, Population Density, High Level Qualification Rate, and Knowledge-Intensive Services. This type of area is well-positioned to benefit from economic recovery. The remainder of the UK is made up of three Rural clusters – 9 clusters in all.
P-squared is built inside the economic clusters and is a hierarchical system with three tiers in order of affluence; 14 ‘Trees’, 41 ‘Branches’, and 157 ‘Leaves’. In addition to census data, P-squared will use insight from the British Population Survey to provide extra descriptive variables, such as lifestyle and income measures. Simon Whalley, data manager, said ‘the aim is to create a classification based on an economic picture of the UK that allows for regular updating from an economic perspective’. www.beacon-dodsworth.co.uk
So, a rich mixture of approaches to a common theme – how best to classify and target consumers in the second decade of the second millennium. Geodemographics reinvents itself yet again!
This article was published in GIS Professional December 2014
Value staying current with geomatics?
Stay on the map with our expertly curated newsletters.
We provide educational insights, industry updates, and inspiring stories to help you learn, grow, and reach your full potential in your field. Don't miss out - subscribe today and ensure you're always informed, educated, and inspired.
Choose your newsletter(s)