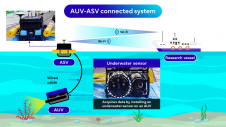
Data Compression
This issue of GIM International presents a Product Survey on mobile mappers: small, lightweight, handy instruments for gathering data and integrating the collected data with digital maps. But how is all this stuff stored in a tiny mobile mapper? Data compression is the magic spell! <i>I know what it is, I know what it does, but how does it work?</i>
Data compression shrinks the size of a dataset so that more data can be stored on the device or transmitted faster over a communication channel than would have been possible without compression. Data compression is used in two main types of applications: data transmission (like communication by voice over the phone), and storage of, for example, raster data or coordinates within a GIS envir-onment.
It was Claude E. Shannon who in 1948 formulated the theory of data compression, both ‘lossless’ and ‘lossy’, in a paper entitled A Mathematical Theory of Communication. In lossless data compression the compressed data after decompression is an exact replica of the original. Reducing or eliminating redundancy, such as repeated patterns, in the data achieves data reduction. In lossy data compression the decompressed data need not be exactly the same as the original, often it suffices to have a reasonably close approximation, so that a certain degree of distortion is allowed between the original and decompressed data. WinZip creates lossless compression; the often-used JPEG algorithm is an example of lossy compression.
Lempel-Ziv-Welch
One of the most popular data compression programs used by mobile mappers is GZIP, which is based on the Lempel-Ziv-Welch (LZW) algorithm. LZW is one of the most common algorithms used in computer graphics, and is also used in popular programs such as ZIP and PKZIP). LZW is a general lossless compression algorithm capable of working on almost any type of data. The algorithm identifies patterns of data (blocks) in the dataset. A particular block is matched to the block in an indexed dictionary. When a match is found, the index of the substring involved is written to the output file.
No dictionary of blocks is available at the onset of compression as this created along redefined lines during the compression process: if the identified block is not present in the dictionary, it is written in and provided with an index. The newly created index is also written to the output file. During decompression the index pointer is read from the compressed file, and if the index pointer is not yet in the data dictionary it is written there. The index is then translated into the block it represents and written to the uncompressed output file. Since the decoder knows that the last symbol of the most recent dictionary entry is the first symbol of the next parse block, possible conflicts during decoding are avoided.
LZW does not require preservation of the dictionary to decode the decompressed file, which again saves storage place. This is accomplished by building up the dictionary along predefined lines making use of a priori knowledge of the data. Suppose that the data consists of a random alternation of two symbols from the alphabet: a and b. First the dictionary is initialised to contain all one-symbol blocks, in this case this is two (a,b) indexed as pos 0 and pos 1, then the combination ab (pos 2) is recognised, next bb (pos 3), followed by the combination ba (pos 4), and so on. If we decompress the string 011024… the character-combination is as follows abbaabba…
Coordinates
In data files containing coordinates patterns will obviously be found because the file is usually limited to a part of a country, a province or local government area. Accordingly, the first series of numbers of the X and Y coordinates are identical for all coordinates and can thus be replaced by an index referring to its position in the dictionary. As a result, the compression ratio of coordinate files with the LZW algorithm is very high. (Compression ratio is the ratio of the size of the original data to the size of the compressed data. For example, when a coordinate file is originally represented by six million bytes and after compression by one million bytes the compression ratio is 6:1, or 83.3%.) Theoretically, the size of the dictionary can grow to infinity, but in practice the size is limited to a recommended length of 4,096 blocks (12 bits); no more entries are added after this limit has been reached.
Value staying current with geomatics?
Stay on the map with our expertly curated newsletters.
We provide educational insights, industry updates, and inspiring stories to help you learn, grow, and reach your full potential in your field. Don't miss out - subscribe today and ensure you're always informed, educated, and inspired.
Choose your newsletter(s)